
Objective:
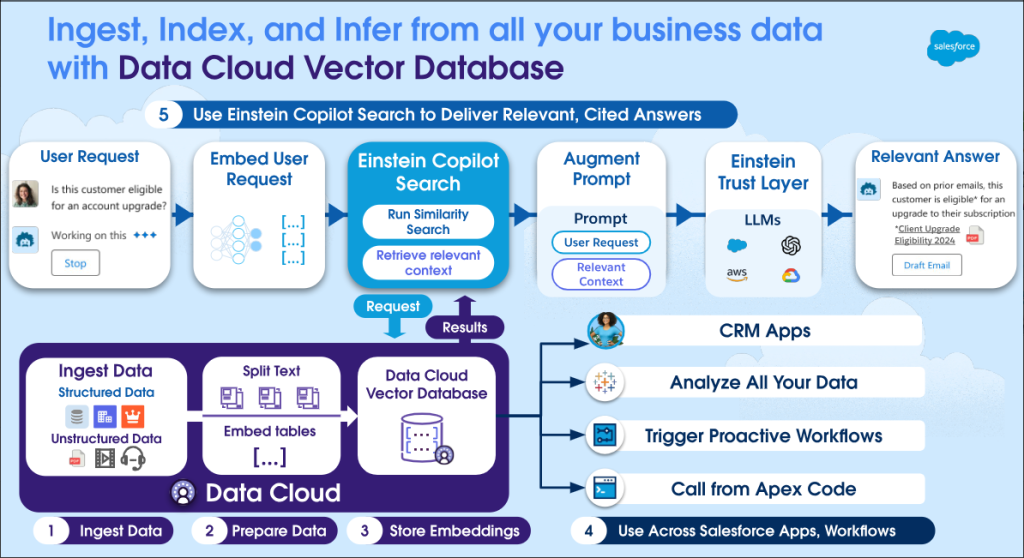
The goal of this project is to create a smooth connection between AWS S3 and Salesforce Data Cloud using a pipeline event. This integration is designed to incorporate unstructured data from AWS S3 into the Data Cloud Vector Database. After the data is indexed in the vector database, Agent Force is utilized to query the data, allowing for efficient retrieval and response generation. This solution improves data management and query performance for unstructured data, offering deeper insights and easier access to information.
KeyFeatures:
Automated Data Ingestion:
Data Embedding in Vector Database:
Indexing for Enhanced Search:
Integration with Agent Force:
Establishing a Notification Pipeline for Data Transfer Between AWS S3 and Salesforce Data Cloud
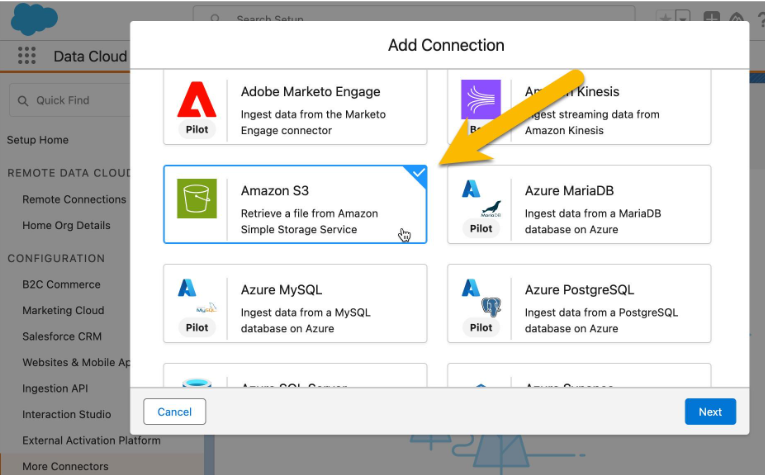
1. Create a connection to a blob store(aws), in Data Cloud Admin Page :
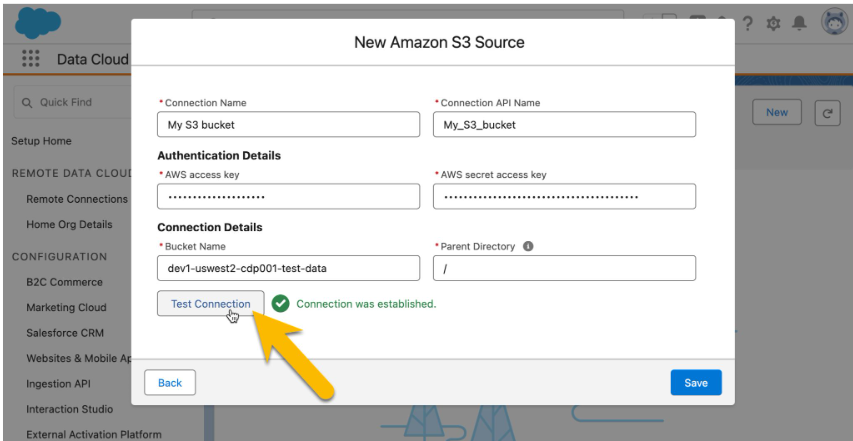
To connect AWS S3 with Salesforce Data Cloud, begin by setting up a connection to the blob store (AWS S3) via the Data Cloud Admin Page. This entails entering information such as the S3 bucket name, access key, and secret key, which enables secure access to the data stored in AWS S3. This connection allows Data Cloud to fetch and handle files from the designated S3 bucket for additional processing.
Note: please click to enlarge the image
{kind=link}
{kind=link}
{kind=link}
2.Create a connection to a blob store(aws), in Data Cloud Admin Page :
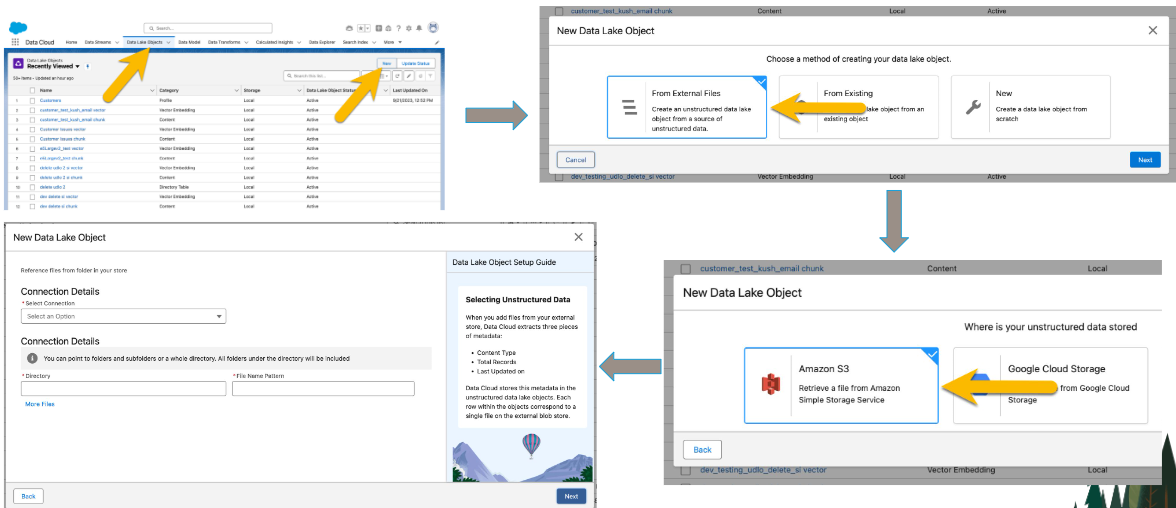
In order to store and manage unstructured data in Salesforce Data Cloud, you need to create a UDLO (Unstructured Data Lake Object). A UDLO acts as a container for unstructured data imported from AWS S3. It defines the structure and schema for how the data will be stored, allowing Data Cloud to index and organize the data for easy querying and analysis.
{kind=link}
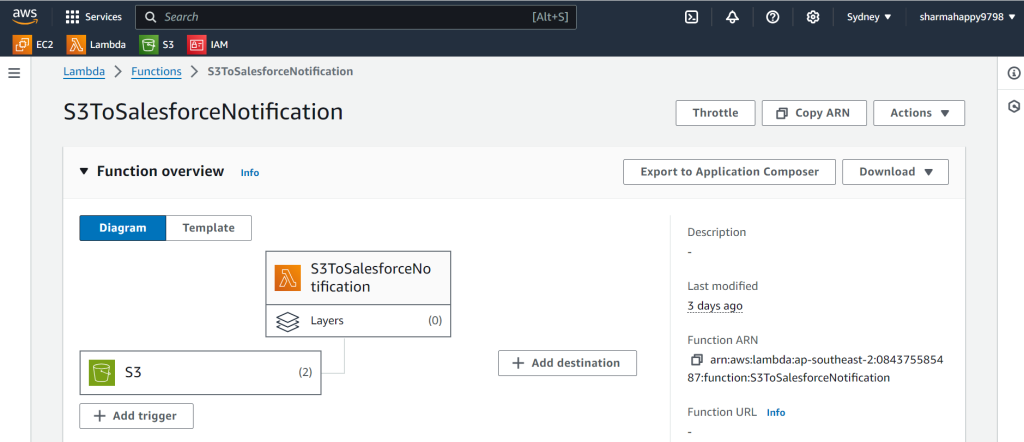
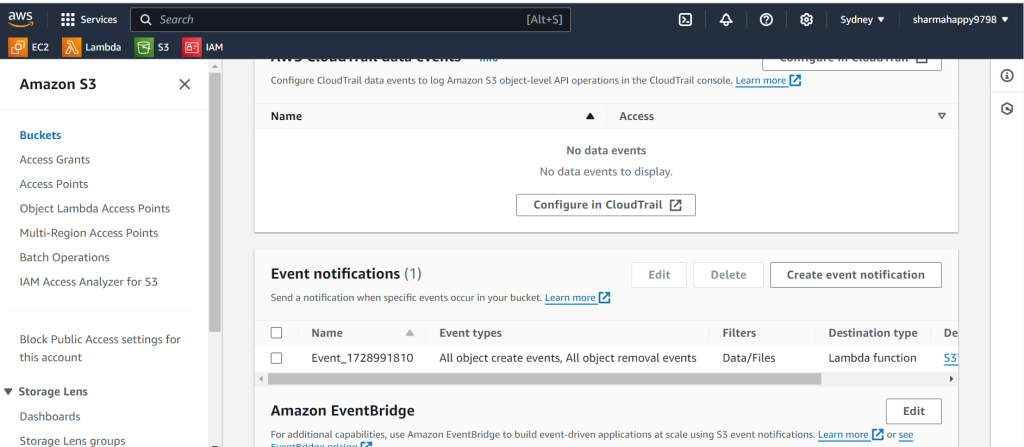
3.In the External blob store(Aws s3) setup notification to datacloud.
In order to receive real-time notifications from Amazon S3 to Salesforce Data Cloud when unstructured data changes, you need to set up a file notification pipeline. This involves creating a connected app in Salesforce with OAuth settings, generating a private-public key pair, and configuring AWS resources such as IAM roles, S3 buckets, AWS Lambda functions, and Secrets Manager. The Lambda function manages file change events in the S3 bucket and triggers notifications to the Data Cloud whenever new data is added, updated, or deleted. Finally, an installer script is provided to automate the setup, ensuring seamless integration between S3 and Data Cloud for data synchronization.
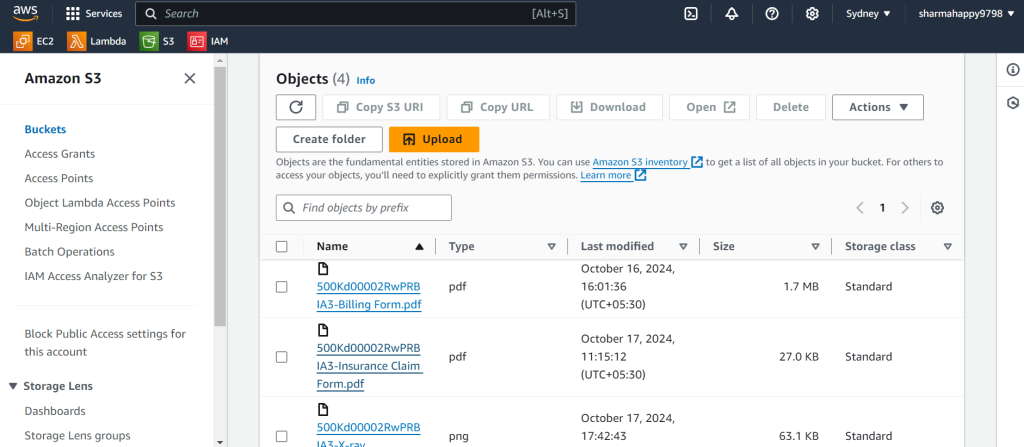
4.Upload Unstructured Data:
To transfer data from AWS S3 to Salesforce Data Cloud, you need to upload the unstructured data files to the specified S3 bucket. This action will trigger an event notification pipeline, which enables Data Cloud to detect the newly added files. Once the files are uploaded, the data will be automatically processed and integrated into the Unstructured Data Lake Object (UDLO) in the Data Cloud. This will make the data ready for indexing and querying.
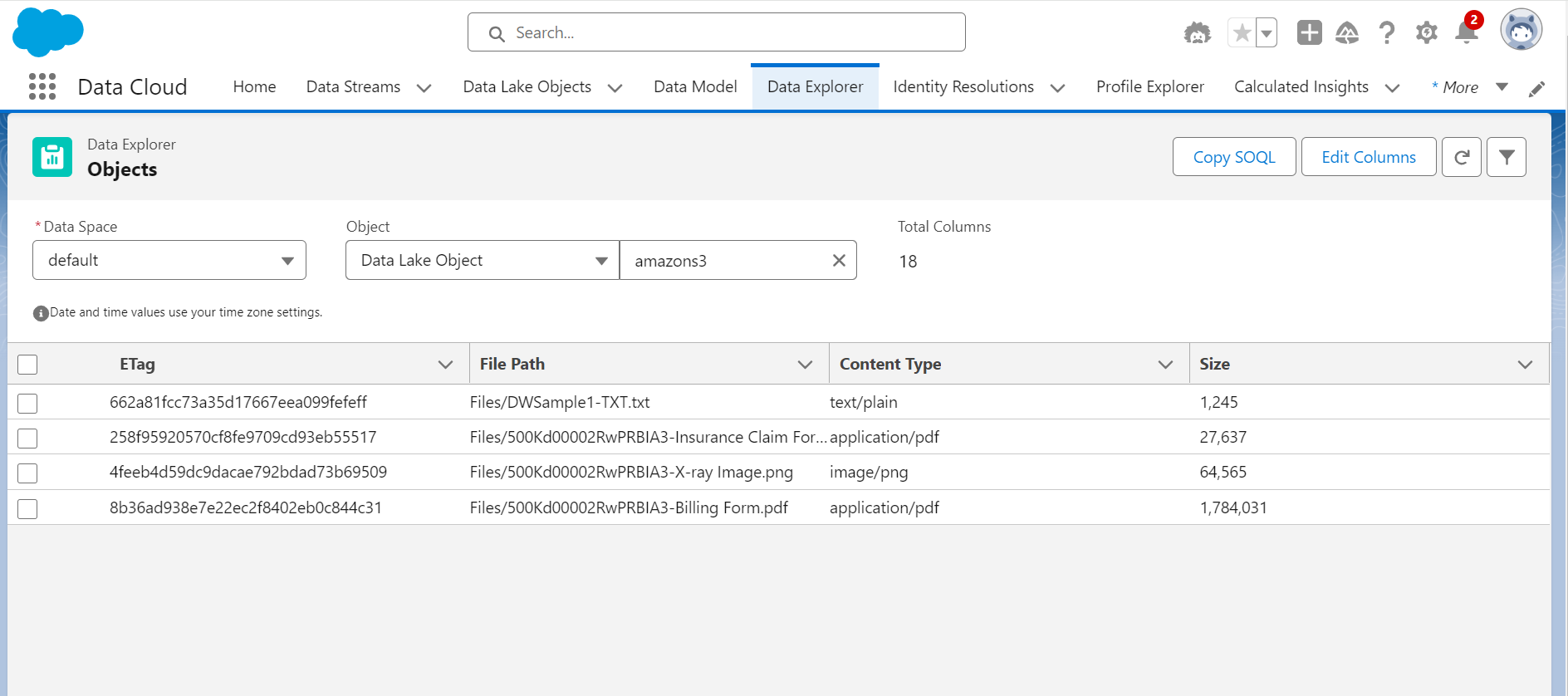
5.Verify that the UDLO shows newly uploaded files
After uploading the unstructured data files to the AWS S3 bucket, please verify that the Unstructured Data Lake Object (UDLO) in Salesforce Data Cloud reflects the newly added files. To do this, navigate to the Data Cloud interface and check the UDLO for the latest entries. This confirmation ensures that the data ingestion process was successful and that the files are correctly indexed and available for querying and analysis within the Data Cloud environment.


Once we verify that all chunk data and indexing processes are functioning correctly, the unstructured data is ready for querying through Agent Force.
Querying Embedded Unstructured Data with Agent Force :
When using the Agent Force feature, it utilizes an Apex-based agent actions flow to search within the system. This flow queries unstructured data and generates a response using AI. The results are then displayed in the Agent Force window, providing users with relevant insights.
